errori di campionamento
In sintesi, i fattori responsabili della generazione di un errore di campionamento sono riconducibili a
- variazione casuale
- selezione viziata
La variazione casuale è dovuta al caso, cioè ad un insieme di cause, piccole o grandi, che agiscono imprevedibilmente su un fenomeno senza che noi possiamo contrastarne l'azione. La variazione casuale ha sottoposto alla nostra osservazione gli individui che costituiscono il campione, per il quale la misura che vogliamo studiare assume un valore più alto o più basso, senza una regola precisa.
influenza del caso
Tutti noi ricorriamo al "caso" per giustificare, ad esempio, il motivo per cui su 100 lanci di una stessa moneta non sempre esce per 50 volte "testa" e per le restanti 50 "croce". Questo stesso motivo (la variazione casuale) vale a giustificare il seguente esempio.
Supponiamo di avere a disposizione due farmaci, A e B, ugualmente efficaci per una determinata sintomatologia, nel senso che guariscono il 50% dei pazienti trattati. Ci proponiamo di fare una nuova sperimentazione per confermare l'efficacia dei due farmaci. Ammettiamo che, in questo esperimento, non sia presente alcun bias (distorsione: differenza, causata da un errore sistematico, tra la stima ottenuta da un campione e la vera caratteristica della popolazione, e quindi che i dati ottenuti siano assolutamente affidabili). Tuttavia, se l'esperimento prevede di esaminare un numero limitato di soggetti per ciascuno dei due trattamenti, può facilmente capitare di osservare che il farmaco A induce guarigione con maggior frequenza rispetto al farmaco B (o viceversa). Questo effetto è dovuto, appunto, alla variazione casuale.

Ovviamente, l'errore di campionamento è condizionato dall'esistenza di variabilità tra gli individui che compongono la popolazione di partenza; se tutti - per assurdo - avessero lo stesso carattere in egual misura, l'esame di qualsiasi numero di individui fornirebbe lo stesso valore, e quindi l'errore di campionamento sarebbe nullo.
La selezione viziata è quella che viene effettuata su un segmento non rappresentativo della popolazione. Questo avviene quando la scelta delle unità che costituiranno il campione viene effettuata con regole non rigorosamente causali. Talvolta, è lo stesso sperimentatore che, definendo delle regole estemporanee volte a neutralizzare - nelle intenzioni - gli effetti del caso e di ottenere un campione più aderente alla popolazione, commette un errore che rende i dati inutilizzabili. Infatti, un campione che non è stato ottenuto correttamente fornisce misurazioni e risultati per i quali è impossibile calcolare il cosiddetto "errore di campionamento".
la selezione viziata è quella effettuata su un campione non rappresentativo
esempio 1: vogliamo accertare la proporzione di persone che si curano con preparati omeopatici in una determinata città. Non potendo esaminare tutti gli individui della città considerata, decidiamo di esaminare un campione di persone. Per comodità, scegliamo le persone che si servono presso le farmacie provviste anche di prodotti omeopatici. Il campione così ottenuto sarà sicuramente composto proprio da molte di quelle persone che assumono preparati omeopatici.
Il nostro campione sarà biassato perché (1) ha selezionato persone che preferiscono la medicina omeopatica, e (2) ha selezionato persone che si servono in Farmacie omeopatiche. Presumibilmente, una maggior quantità di individui del nostro campione risulterà privilegiare il trattamento omeopatico e dunque potremmo erroneamente concludere che "moltissime persone non ricorrono alle terapie tradizionali".
|
|
esempio 2: il campione prelevato con una biopsia epatica rappresenta circa 1/50.000 dell'organo. Essendo il campione così piccolo rispetto all'intero organo, esiste la possibilità di ampie variazioni da un campione all'altro. Inoltre, poichè il campione viene esaminato, in genere, allo scopo di diagnosticare una malattia dell'intero fegato, è possibile che il processo di inferenza sia viziato. Ad esempio, si preleva un campione di tessuto sano in un organo ammalato.
|
In conclusione, si può affermare che soltanto quando la scelta degli individui che compongono il campione è stata dettata dal puro e semplice caso, è possibile prevedere e calcolare l'entità della differenza tra campione e popolazione. In caso contrario, il campione si dice "distorto" o "biassato". Con un campione distorto, non è possibile calcolare l'errore di campionamento ed i dati ottenuti saranno difficilmente utilizzabili.
Più precisamente, per "bias" si intende un processo, effettuato in qualsiasi stadio della inferenza, che tende a fornire risultati che si discostano sistematicamente dai valori veri.
A differenza del bias (che influenza i dati sistematicamente in una direzione o nell'altra), la variazione casuale fornisce dati che possono essere parimenti al di sopra o al di sotto del valore vero. Di conseguenza, la media di molte osservazioni non-biassate si avvicina al valore vero della popolazione, anche se i singoli dati utilizzati per ottenere la media possono discostarsi di molto dal valore vero.
esampio: nel disegno in basso, sono raffigurati due bersagli:
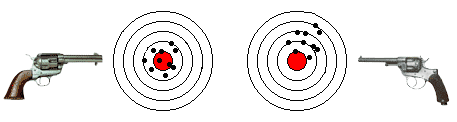
- bersaglio a sinistra: mostra la rosata dei fori prodotti da 10 proiettili sparati da un esperto tiratore che ha usato un revolver con il mirino ben regolato. L'insieme dei fori si può considerare come un campione delle infinite possibili combinazioni di 10 colpi che quel tiratore può ottenere sparando con il suo revolver. Come si vede, i fori hanno una disposizione casuale (dovuta alle piccole differenze esistenti tra i proiettili ed a piccole oscillazioni del braccio) ma tendono a disporsi attorno al centro del bersaglio.
- bersaglio a destra: mostra la rosata dei fori prodotti da 10 proiettili sparati dallo stesso tiratore che però ha usato un revolver con il mirino non ben regolato. Anche in questo caso, i fori hanno una disposizione casuale, ma tendono ugualmente a disporsi attorno ad un punto che non corrisponde al centro del bersaglio.
Supponiamo (figura sotto) di non conoscere la posizione del centro bersaglio (che, fuor di metafora, corrisponde alla VERA caratteristica della popolazione in studio, la quale in effetti non è mai nota).
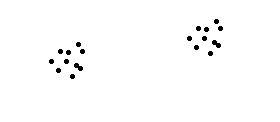 Con un buon campionamento (che equivale ad un revolver ben regolato) otterremo il campione raffigurato a sinistra; se, invece, il campione sarà affetto da bias, otterremo un campione come quello a destra.
Con un buon campionamento (che equivale ad un revolver ben regolato) otterremo il campione raffigurato a sinistra; se, invece, il campione sarà affetto da bias, otterremo un campione come quello a destra.
Ora, in base ai dati ottenuti dalla figura sopra, proviamo a fare una inferenza sulla vera caratteristica della popolazione (figura in basso).
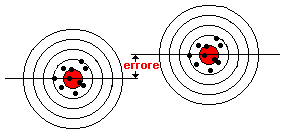
E' facile convincersi che, se utilizzeremo il campione di sinistra (cioé quello del revolver ben regolato) l'inferenza sarà ragionevolmente accurata, mentre con il campione affetto da bias (a destra), saremo indotti a ritenere che il centro del bersaglio sia spostato rispetto al reale. In quest'ultimo caso, fuor di metafora, non riusciremo a stimare correttamente la vera caratteristica della popolazione: commetteremo un errore.
|
Marcello Guidotti, copyright 2003
questa pagina può essere riprodotta su qualsiasi supporto o rivista purché sia citata la fonte e l'indirizzo di questo sito (ai sensi degli artt. 2575 e 2576 cc. Legislazione sul diritto d'autore). Le fotografie sono tratte da siti web e sono, o possono ritenersi, di pubblico dominio purché utilizzate senza fini di lucro. Le immagini di prodotti presenti nel sito hanno unicamente valenza esemplificativa oltre che, eventualmente, illustrare messaggi fuorvianti e non vi è alcun richiamo diretto o indiretto alla loro qualità e/o efficacia il cui controllo è affidato alle autorità regolamentatorie.